
Method to consume local data in LLM interactions
The widespread adoption of Large Language Models (LLMs) has rendered them an indispensable tool for conducting rapid research, document uploading and summarization, conducting in-depth research on relevant topics, and even requesting the refinement of code. However, it is crucial to acknowledge that LLMs possess a finite knowledge base, characterized by a specific cutoff date. This cutoff date determines the level of up-to-date information embedded within the LLM, resulting in a lack of awareness of contemporary events such as the current date or the Chancellor of Germany.
There are methods to enhance this, such as copying your data into the prompt, all in an effort to provide the LLM with contextual information that makes the response contemporary and relevant to your requirements. You can create integration with tools to perform tasks such as web searches, utilize Retrieval Augmented Generation (RAG) to integrate your custom sources of information, or upload documents to provide the LLM with context. However, the challenge with all these approaches is that they are bespoke methods of feeding information to an LLM, necessitating the creation of custom code or plugins tailored for user interfaces that interact with LLMs. What was required to significantly simplify the management and consumption of this process was a standardized method of interfacing with diverse sources of information and various LLMs. This is precisely what the Model Context Protocol (MCP), which was open-sourced by Anthropic in 2024, aims to address.
Anthropic appears to have carefully considered this issue and has devised a method for addressing it by enabling the standardization of data presentation to LLM agents and the integration of external data sources to enhance the relevance of data retrieval for users.
What is it
The documentation for the MCP can be found here as well as the Python, TypeScript, Java, and Kotlin SDKs, and the latest specifications of the protocol.
In essence, the protocol is structured into a client-server model, wherein the client, akin to an LLM agent, establishes connections with one or more servers to facilitate the provision of data.
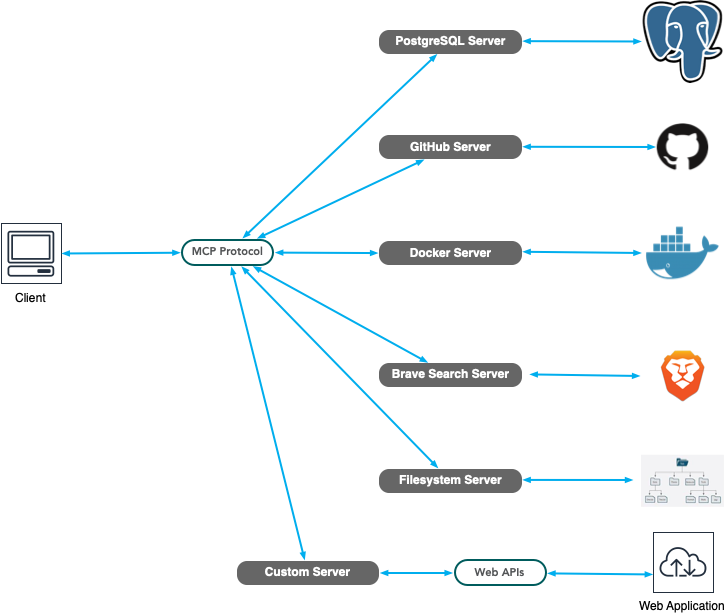
These servers as an initial subset could be:
- Filesystem access, databases connectors, or web-based applications such as, Google Drive, Google Maps, Slack…
- Git, GitHub, GitLab, and Sentry access
- Community-provided integrations with Docker, K8s, or even Spotify.Web searching using, for example, the Brave search API
- Integration with a Knowledge-Based (KB) system such as AWS Knowledge Base using Bedrock Agent
- Commercial integration to provide API access to corporate resources and data like Cloudflare, Qdrant, Stripe
This makes it possible to provide extensive context to augment LLM training and optimizations for data that is relevant to an end user using an almost plug-and-play simple plugin like interface.
How Does this all work:
An MCP server offers three primary capabilities that can be utilized by an LLM:
- Resources: File-like data that can be read by clients (like API responses or file contents)
- Tools: Functions that can be called by the LLM (with user approval)
- Prompts: Pre-written templates that help users accomplish specific tasks
Utilizing the Anthropic-provided Claude client as a client example, we can configure it to integrate with servers by simply adding entries to a JSON configuration file. For instance, the configuration for Filesystem access would be as follows:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/kwanguhu/Downloads",
"/Users/kwanguhu/Desktop"
]
}
}
}
This instruction specifies the execution of the npx command, which is part of a locally installed Node instance. The command should be executed with the necessary arguments to connect to an MCP server. Access to the server is restricted to a list of provided directories that would be accessible to the LLM for access. Subsequently, the MCP Filesystem server is initiated in the background and awaits queries through standard input/output (stdio). Currently, initial Claude client interactions are limited to servers whose interfaces can be accessed through stdio connections. This implies that all servers must be running on the local machine, with the client, in order to receive input on the stdio interfaces. For servers that run remotely, such as the Home Assistant MCP server, that uses Server-Sent Events (SSE) to communicate, you would need to run a local stdio to SSE transport proxy in order to interact with it. I will cover that in a future blog post on using the Home Assistant MCP Server from an LLM.
After updating the Claude client configuration JSON file and restarting the client, you can subsequently utilize it to query and access the file contents stored in the shared directories. This functionality enables you to read data from existing files or generate new files based on interactions with the LLM.
Asking Claude which directory it has access to prompts it to recognize this as a query pertaining to a local filesystem. Subsequently, it identifies the configured servers that offer tools capable of retrieving this information. The Filesystem server provides the list_allowed_directories tool, prompting Claude to request permission for its usage.
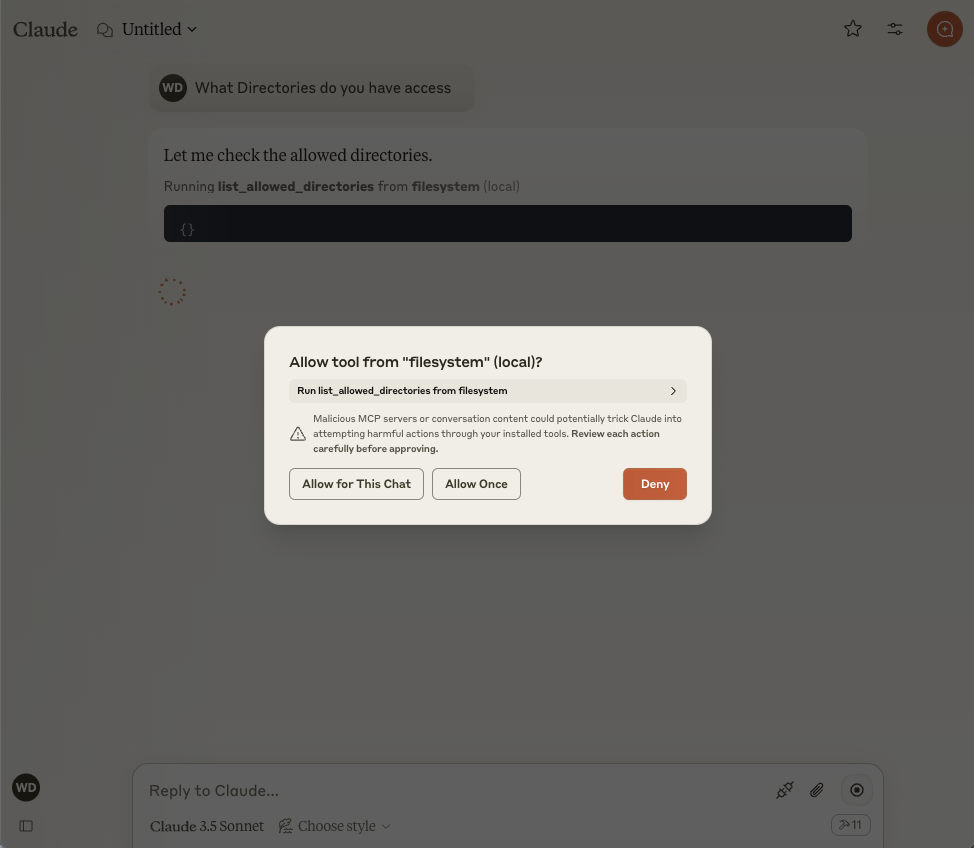
If you permit the tool to be run, it will retrieve data from the Filesystem server, which will provide a list of directories that it has access to.
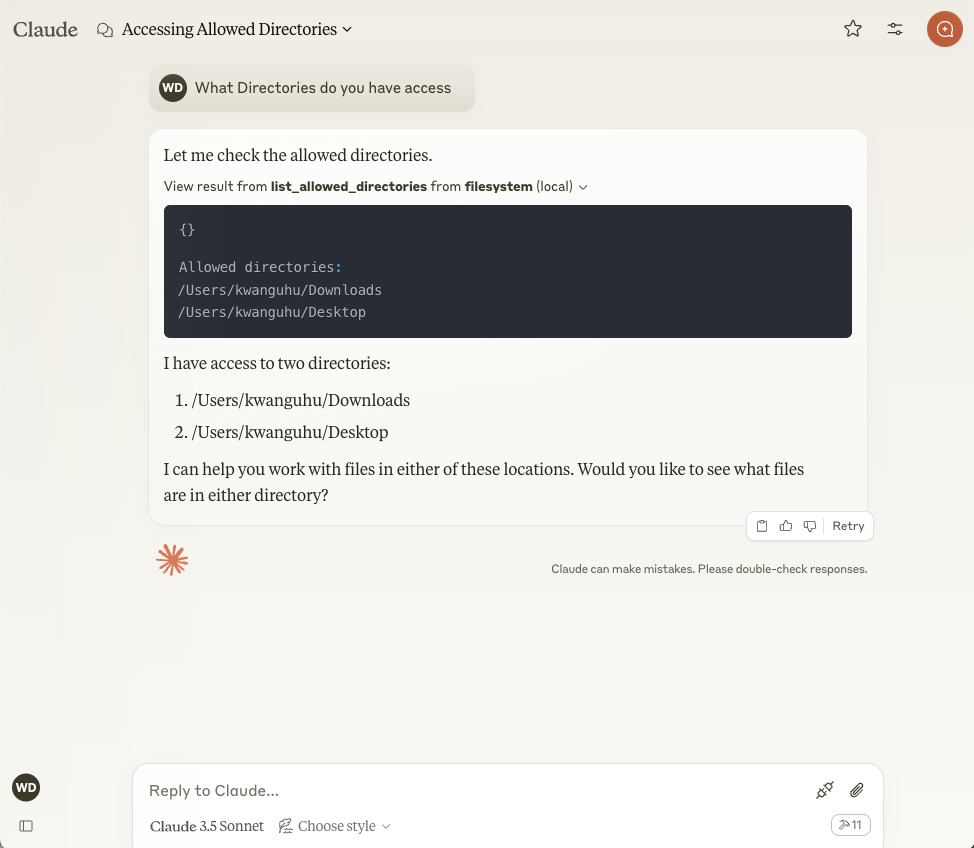
At this point, you can interact with the contents of the directories, read, create, or even delete files.
As I have demonstrated, I firmly believe that MCP will significantly simplify the process for non-developers to enhance the functionality of their interactions with LLMs by incorporating pertinent context. The ecosystem surrounding MCP is experiencing rapid growth, with numerous servers being established by both companies and individuals to augment the user experience and facilitate seamless integration of personal data with LLM-based clients.